Quarterly Distribution Densities
This graph was created for an assignment in a visualization class.
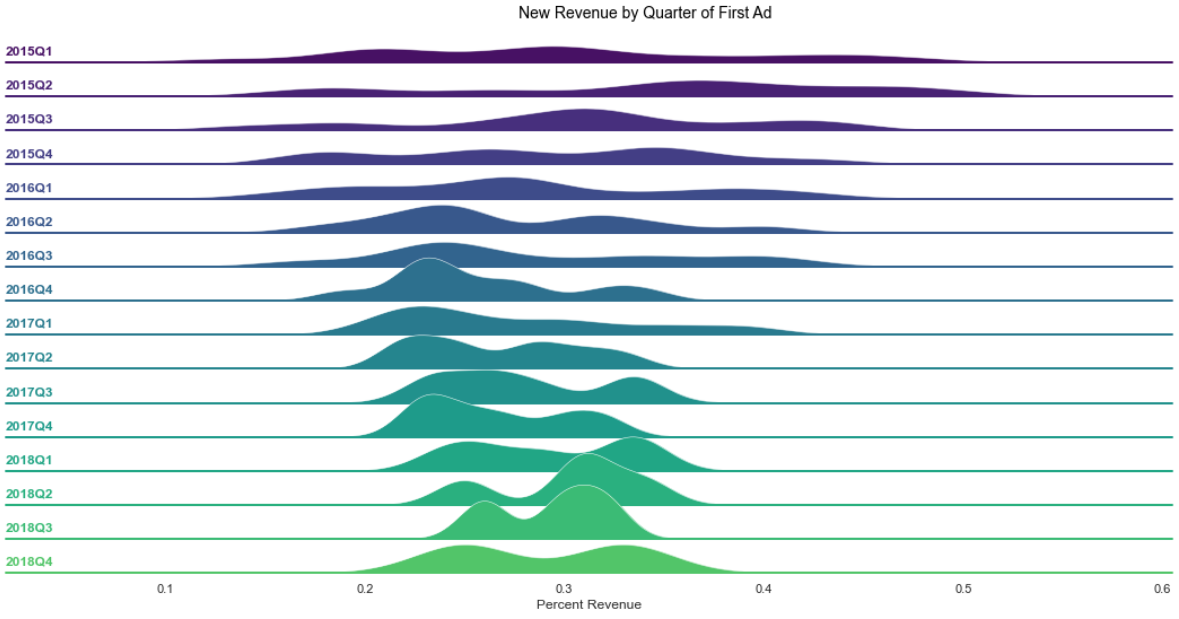
I will give details about the graph and then as usual I will discuss the code used to generate it.
Quarterly Revenue Distribution Density
The data for this graph was given to me as part of a class assignment so I do not have a source for it. The data is available here. Note that the data is in an unusual, triangle-shaped format; I first had to change it to a tidy format using pd.melt().
The graph is inspired by a Seaborn example which I thought was beautiful and wanted to re-create. Note that the lower sections of the plot are drawn over sections higher on the page.
This data was collected from clients who were utilizing a new advertising tool in order to track the revenue from that tool, as measured in percentage of total client revenue. It is not known how many clients there are, and the dataset is intentionally vague.
On the left are quarters of each year from the beginning of 2015 to the end of 2018. These groups represent the first quarter that an ad was created using the new tool. The x-axis, percent revenue, is a measurement of clients’ percentage of revenue generated from the new advertising tool.
The dataset indicates that new clients were added as the data grows more recent, which lends to the fact that the dataset is triangle-shaped; there is simply more data for older clients. Thus, you can see the distribution widen from the bottom to the top of the page.
Code Breakdown
Imports
import pandas as pd
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
import seaborn as sns
Code Chunk
dfk=df.loc[df["YearQuarter"] != "2019Q1"]
#Seaborn Ridge Plot
sns.set_theme(style="white", rc={"axes.facecolor": (0, 0, 0, 0)})
#FacetGrid Object
pal = sns.color_palette("viridis", 21)
g = sns.FacetGrid(dfk, row="YearQuarter", hue="YearQuarter", aspect=30, height=.5, palette=pal)
#densities
g.map(sns.kdeplot, "Values",
bw_adjust=.5, clip_on=False,
fill=True, alpha=1, linewidth=1)
g.map(sns.kdeplot, "Values", clip_on=False, color="w", lw=0.5, bw_adjust=.5)
g.map(plt.axhline, y=0, lw=2, clip_on=False)
#function to label plot
def label(x, color, label):
ax = plt.gca()
ax.text(0, .2, label, fontweight="bold", color=color,
ha="left", va="center", transform=ax.transAxes)
#apply function
g.map(label, "Values")
g.set(xlabel="Percent Revenue")
#set subplots to overlap
g.fig.subplots_adjust(hspace=-.25)
#remove axis details
g.set_titles("")
g.set(yticks=[])
g.despine(bottom=True, left=True)
plt.annotate('New Revenue by Quarter of First Ad',
xy=(0, 0), xycoords='axes fraction', fontsize=14,
xytext=(.44, 12.2), textcoords='axes fraction',
horizontalalignment='left', verticalalignment='top', color='black')
Section Breakdown
dfk=df.loc[df["YearQuarter"] != "2019Q1"]
#Seaborn Ridge Plot
sns.set_theme(style="white", rc={"axes.facecolor": (0, 0, 0, 0)})
This first section of code sets the data to be used by the graph as well as the seaborn theme. First, a new dataframe is created from the original dataframe, minus 2019Q1. This is done because 2019Q1 has a single entry, and the plotting function cannot handle it. The facecolor parameter is set to (0,0,0,0); this specifies the RGB values and the alpha value. Because the alpha is set to zero, the facecolor is transparent.
#FacetGrid Object
pal = sns.color_palette("viridis", 21)
g = sns.FacetGrid(dfk, row="YearQuarter", hue="YearQuarter", aspect=30, height=.5, palette=pal)
This section of code sets the facet grid which allows the plots to be plotted one after another in a stack. First, the color palette is set to viridis, which ranges from purple to a bright yellow. Despite there being only 16 groups plotted, the number of colors is set to 21. This is done for readability.
The facet grid is then created using Seaborn’s FacetGrid() method. This does not actually plot the data, which is specified using the dataframe and row. The hue is set as a dimension which iterates on each listed group. The aspect and height variables specify the size of the graph, and the palette is called in at the end.
#densities
g.map(sns.kdeplot, "Values", bw_adjust=.5, clip_on=False, fill=True, alpha=1, linewidth=1)
g.map(sns.kdeplot, "Values", clip_on=False, color="w", lw=0.5, bw_adjust=.5)
g.map(plt.axhline, y=0, lw=2, clip_on=False)
In this section of code, the data is plotted. Seaborn’s kdeplot() method is mapped to the facet grid twice. The first instance fills the curves with a solid color, and the second instance outlines the curves with a white border. The bw_adjust parameter controlS curve smoothing. And specifying clip_on=False allows the data to be plotted beyond the extent of the axes. It is worth noting that setting this to True does not prevent the curves from overlapping one another.
Lastly, a horizontal line is plotted along the axis for each curve at y=0 and with line width 2.
#function to label plot
def label(x, color, label):
ax = plt.gca()
ax.text(0, .2, label, fontweight="bold", color=color,
ha="left", va="center", transform=ax.transAxes)
In this section of code, a function is defined in order to label the plot. The function calls for the curve, the color of the curve, and the label to be applied. It then gets the current axis, and adds text to that axis with ax.text. First, the coordinates for the text are specified as x=0, y=0.2. Then the label is read from the list of variables. The horizontal and vertical alignments are specified with ha and va. transform=ax.transAxes causes the coordinates specified earlier to be applied as axes fractions.
#apply function
g.map(label, "Values")
g.set(xlabel="Percent Revenue")
The text plotting function is then applied using the map() method. This method indicates that the labeling function previously specified is to be used. FacetGrid.map inherently passes a color object into the function. Because hue was specified as a dimension in an earlier block of code, map() will also pass a label into the text function: the current quarter.
The second line in this code section sets the x label.
#set subplots to overlap
g.fig.subplots_adjust(hspace=-.4)
This line is what causes the plots to overlap. hspace is adjusted with a negative modifier, which removes height from each facet.
#remove axis details
g.set_titles("")
g.set(yticks=[])
g.despine(bottom=True, left=True)
Because this plot is composed of multiple plots on top of each other, it is necessary to remove elements of the figure that would be plotted in excess. This includes the title, the y-ticks, and the spines (which normally denote the boundaries of the data area).
plt.annotate('New Revenue by Quarter of First Ad',
xy=(0, 0), xycoords='axes fraction', fontsize=14,
xytext=(.44, 10), textcoords='axes fraction',
horizontalalignment='left', verticalalignment='top', color='black')
Since all titles were set to an empty value in the section above, it is necessary to annotate the plot in order to add a title. xytext specifies the coordinates of the text, textcoords makes it so that the coordinates specify fractions of the axes, the fontsize and color are set, and vertical and horizontal alignment are specified (top left corner of the text box).